Appearance
Bitcask:一个用于高速键/值数据的日志结构哈希表
作者:Justin Sheehy, David Smith(灵感来自 Eric Brewer)
所属公司:Basho Technologies
邮箱:justin@basho.com, dizzyd@basho.com
Bitcask 的起源与分布式数据库 Riak 的历史紧密相连。在 Riak 键/值集群中,每个节点都使用可插拔的本地存储;几乎任何形态的键/值存储都可以用作每个主机的存储引擎。这种可插拔性使得 Riak的开发可以并行化,因此存储引擎可以在不会影响其他代码库的情况下进行改进和测试。
这样的键值存储已经有很多,包括但不限于 Berkeley DB、Tokyo Cabinet 和 Innostore。我们在评估这些存储引擎时,会考量许多的目标,包括:
- 单条数据读写的低延时
- 高吞吐量,尤其是在写入随机传入的数据流时
- 能够处理远大于内存(RAM)容量的的数据集而不会性能下降
- 崩溃友好性,包括快速恢复和不丢失数据两方面
- 易于备份和还原
- 相对简单、易于理解的代码结构和数据格式
- 在高访问负载或大容量下的行为可预测
- 在Riak中,提供易于使用的默认使用许可证
上面的这些目标,部分实现是比较容易的,要全部实现就不那么容易了。
当时可用的本地键/值存储系统(包括作者编写的那些)在实现上述所有目标方面都不理想。我们正在与 Eric Brewer 讨论这个问题时,他提出了一个关于哈希表日志合并的关键见解:这样做有可能使其变得与 LSM-树一样快甚至更快。
这引导我们以新的视角去探索日志结构(log-structured)文件系统中使用的一些技术,这些技术在20世纪80和90年代被首次开发。这种探索促成了Bitcask 的研发,这是一个能够非常好地满足上述所有目标的存储系统。虽然 Bitcask 最初是为了在 Riak 下使用而开发的,但它被构建为通用的本地键/值存储系统,也可以为其他应用程序所用。
我们最终采用的模型在概念上非常简单。一个 Bitcask 实例就是一个目录,我们强制规定在一个给定的时间点只有一个操作系统进程可以打开该 Bitcask 进行写入。您可以将该进程视为实质上的“数据库服务器”。在任何时刻,该目录中都有一个文件是服务器进行写入的“活跃”文件。当该文件大小达到阈值时,它将被关闭,并创建一个新的活跃文件。一旦文件被关闭(无论是故意关闭还是由于服务器退出),它就被视为是不可变的,并且永远不会再被打开进行写入。
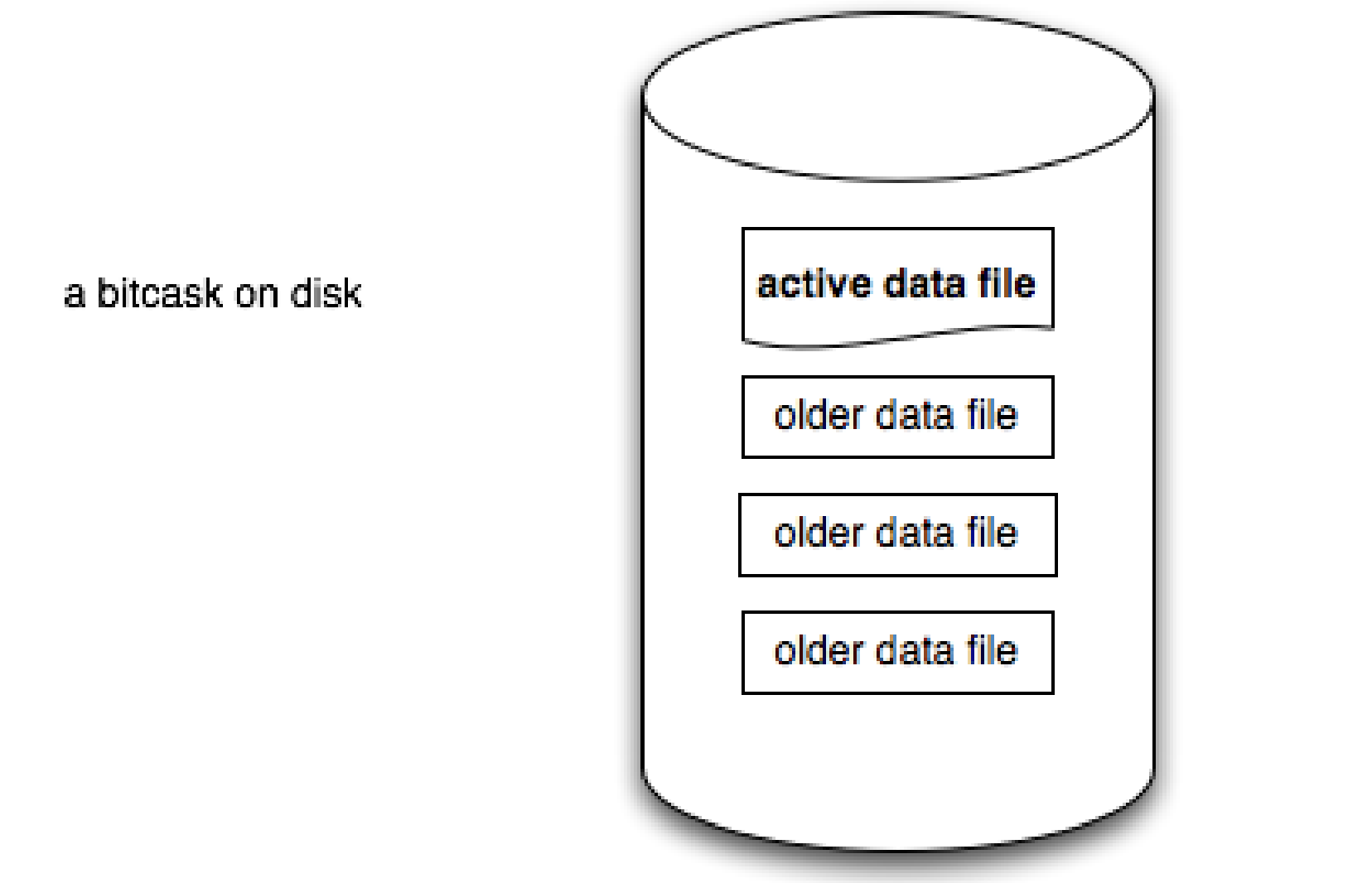
活动文件只能通过追加(Appending) 写入,这意味着顺序写入不需要磁盘寻道。为每个键/值条目写入的格式很简单:
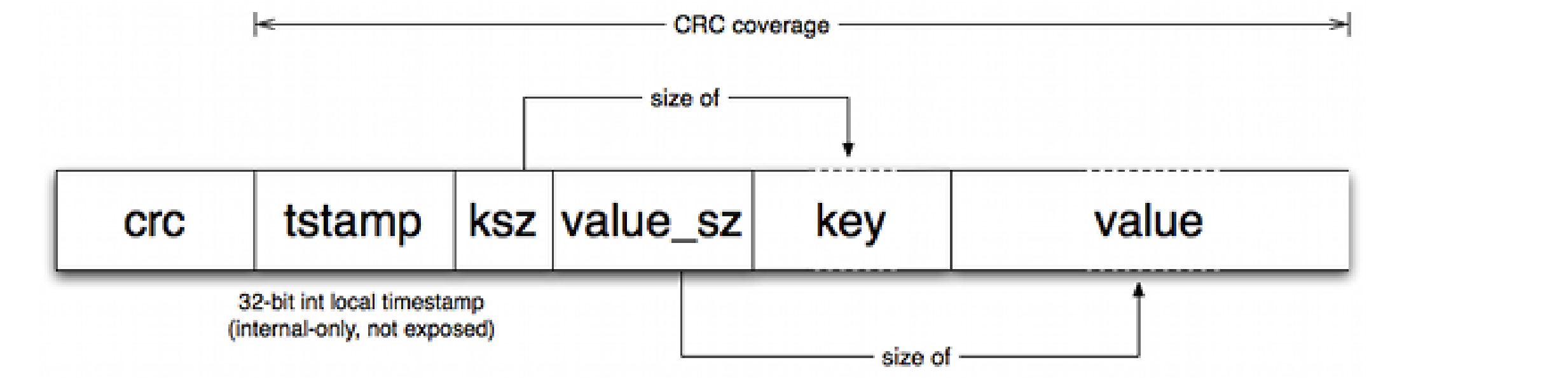
格式说明:(翻译者添加)
- crc(4 字节):该条目其余部分的 32 位 CRC 校验和。
- tstamp(4 字节):时间戳(以秒为单位),表示条目写入的时间。
- ksz(4 字节):键的大小(以字节为单位)。
- value_sz(4 字节):值的大小(以字节为单位)。
- key(ksz 字节):实际的键。
- value(value_sz 字节):实际的值。
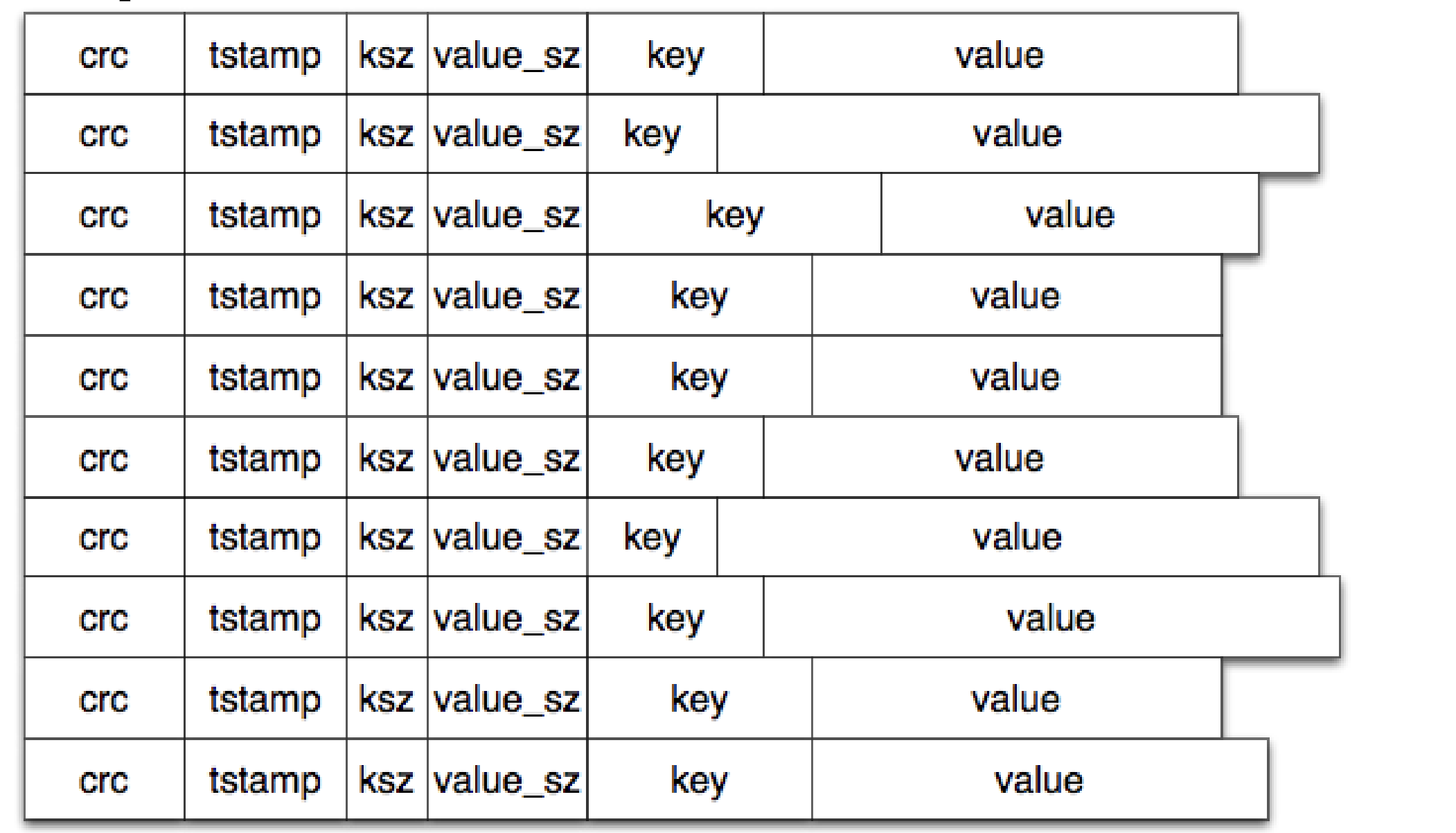
每次写入时,都会向活动文件追加一个新条目。请注意,删除操作只是写入一个特殊的墓碑值(译者按:一个标记,表示对应数据被删除) ,该值将在下次合并时被移除。因此,Bitcask 数据文件只不过是这些条目的线性序列:
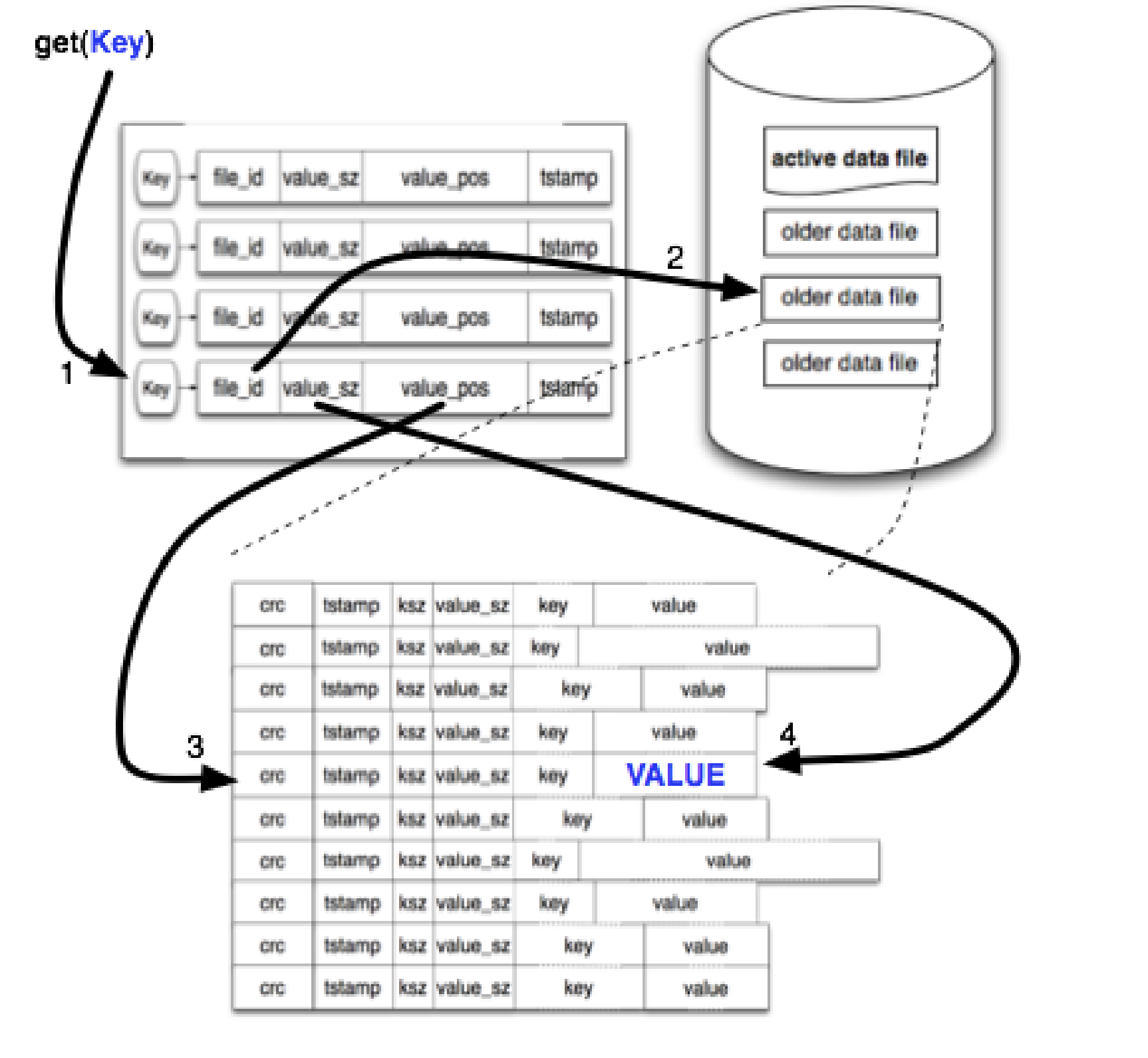
在追加完成后,一个称为 “keydir” 的内存结构会被更新。keydir 就是一个哈希表,它将 Bitcask 中的每个键映射到一个固定大小的结构,该结构给出该键最近写入条目所在文件的文件ID、偏移量和条目大小。 
当写入发生时,键目录(keydir)会原子性地更新为最新数据的位置。旧数据仍然存在于磁盘上,但任何新的读取都将使用键目录(keydir)中可用的最新版本。正如我们稍后将看到的,合并过程最终会移除旧值。
读取一个值很简单,并且最多只需要一次磁盘寻道(single disk seek)。我们在键目录(keydir)中查找键,然后使用该查找返回的文件 ID(file_id)、位置(position)和大小(size)读取数据。在许多情况下,操作系统的文件系统预读缓存使得该操作比预期的要快得多。
随着时间的推移,这个简单模型可能会占用大量空间,因为我们只是写出新值而不触及旧值。一个我们称为 “合并(Merging)” 的压缩(Compaction) 过程解决了这个问题。合并过程遍历 Bitcask 中所有非活动(即不可变的)文件,并产生一组数据文件作为输出,这些数据文件仅包含每个键的“存活(live)”或最新版本。
完成此操作后,我们还会在每个数据文件旁边创建一个 “提示文件(hint file)”。这些文件本质上类似于数据文件,但它们不包含值(Value),而是包含值在对应数据文件中的位置(position)和大小(size)。
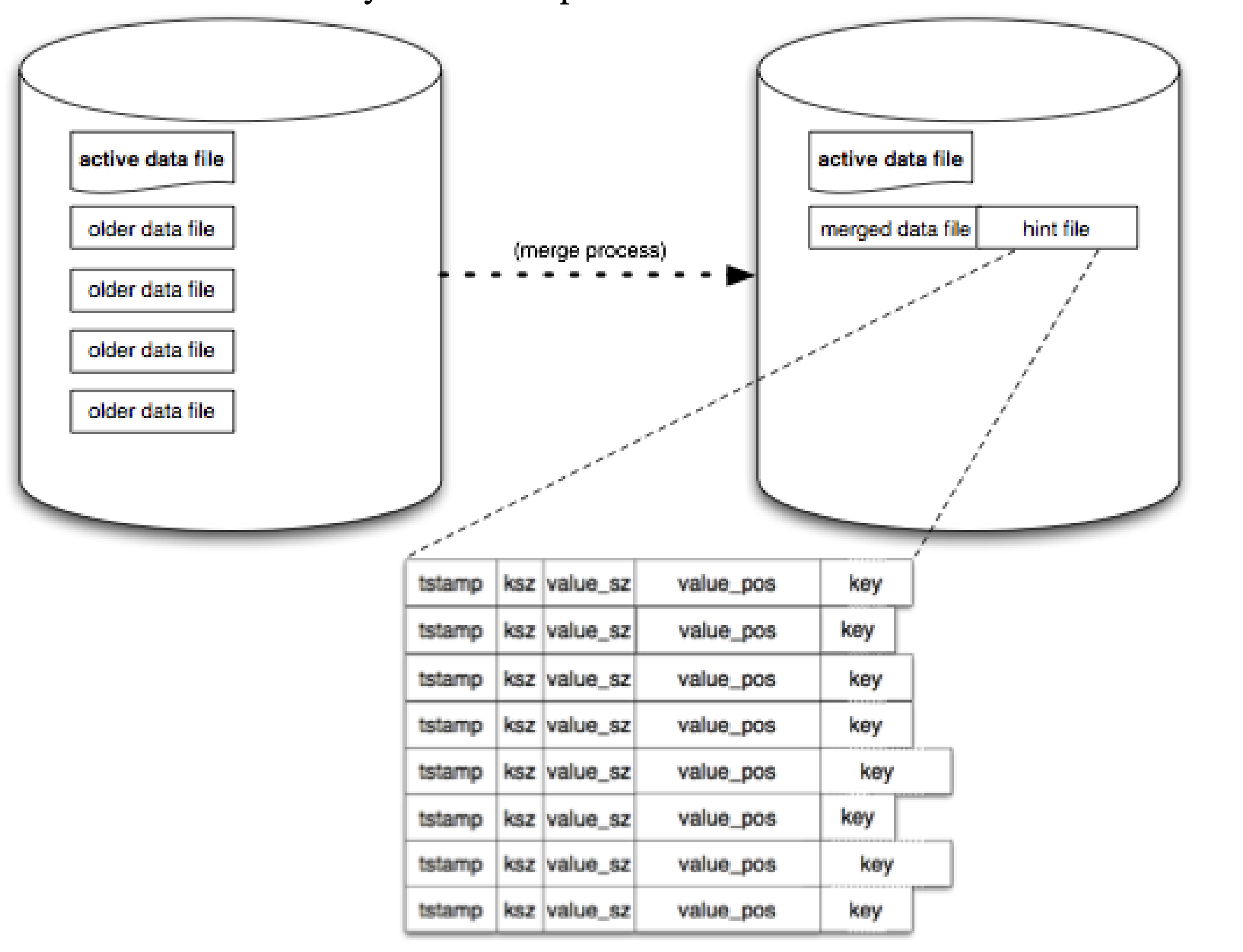
当一个 Erlang 进程打开一个 Bitcask 时,它会检查同一 Erlang VM 中是否已经有另一个进程在使用该 Bitcask。如果有,它将与该进程共享键目录(keydir)。如果没有,它将扫描目录中的所有数据文件以构建一个新的键目录(keydir)。对于任何有提示文件( hint file)的数据文件,将扫描提示文件,这样可以大大加快启动时间。
这些基本操作就是 Bitcask 系统的本质。显然,我们并未试图在本文档中暴露操作的每一个细节;此处我们的目标是帮助您理解 Bitcask 的通用机制。对于我们略过的一些领域,还有一些补充说明是很有必要的:
- 我们提到我们依赖操作系统的文件系统缓存来提高读取性能。我们也讨论过添加 Bitcask 内部的读取缓存,但鉴于目前我们免费获得的收益很大,尚不清楚这样做能带来多少回报。
- 我们将很快展示针对各种 相识API的本地存储系统的基准测试。然而,我们最初对 Bitcask 的目标不是成为最快的存储引擎,而是获得“足够”的速度以及代码、设计和文件格式的高质量和简洁。也就是说,在我们最初的简单基准测试中,我们看到了 Bitcask 在许多场景下轻松超越其他快速存储系统。
- 一些最难的实现细节对大多数外部人士来说也是最不感兴趣的,因此我们没有在这份简短文档中包含(例如)键目录(keydir)内部锁定方案的描述。
- Bitcask 不会对数据进行任何压缩,因为这样做的成本/效益很大程度上取决于具体应用。
让我们回顾一下我们开始时的目标:
- 单条数据读写的低延时:Bitcask 很快。我们计划很快进行更彻底的基准测试,但在我们早期的测试中,典型的中位数延迟在亚毫秒级(并且较高的百分位数也相当不错),我们有信心它可以满足我们的速度目标。
- 高吞吐量,尤其是在写入随机传入的数据流时:在配备慢速磁盘的笔记本电脑上进行早期测试时,我们看到了每秒 5000-6000 次写入的吞吐量。
- 能够处理远大于 RAM 的数据集而不会性能下降:上述测试使用了超过系统 RAM 容量 10 倍的数据集,并且在该点未显示出行为变化的迹象。考虑到 Bitcask 的设计,这与我们的预期一致。
• 崩溃友好性,包括快速恢复和不丢失数据:由于数据文件和提交日志在 Bitcask 中是同一个东西,恢复是微不足道的,不需要“重放(replay)”。提示文件可用于加快启动过程。
• 易于备份和恢复:由于文件在轮换后是不可变的,备份可以使用操作员喜欢的任何系统级机制轻松完成。恢复只需要将数据文件放入所需目录即可。
• 相对简单、易于理解(从而可支持)的代码结构和数据格式:Bitcask 概念简单,代码干净,数据文件非常易于理解和管理。我们对支持构建在 Bitcask 之上的系统感到非常放心。
• 在高访问负载或大容量下的行为可预测:在高访问负载下,我们已经看到 Bitcask 表现良好。到目前为止,它只处理过两位数 GB 的容量,但我们很快就会用更大的容量测试它。Bitcask 的形态使得我们预计它在更大容量下性能不会太不同,唯一可预测的例外是键目录(keydir)结构会随着键数量的增加而少量增长,并且必须完全装入 RAM。这个限制在实践中是次要的,因为即使有数百万个键,当前的实现使用的内存也远低于 1 GB。
总之,考虑到这一组特定的目标,Bitcask 比我们当时可用的任何其他东西都更适合我们的需求。
API 非常简单:
| API | 函数描述 |
|---|---|
| bitcask:open(DirectoryName, Opts) → BitCaskHandle | {error, any() } | 使用附加选项打开一个新的或现有的 Bitcask 数据存储。有效选项包括read_write(如果此进程将是写入者而不仅仅是读取者)和 sync_on_put(如果此写入者希望在每次写入操作后同步写入文件)。 该目录必须可由此进程读写,并且一次只能有一个进程以 read_write 方式打开 Bitcask。 |
| bitcask:open(DirectoryName) → BitCaskHandle| {error, any() } | 以只读方式打开一个新的或现有的 Bitcask数据存储。该目录及其中的所有文件必须可由此进程读取。 |
| bitcask:get(BitCaskHandle, Key) → not_found| {ok, Value } | 从 Bitcask 数据存储中按键检索值。 |
| bitcask:put(BitCaskHandle, Key, Value) → ok| {error,any() } | 在 Bitcask 数据存储中存储键和值。 |
| bitcask:delete(BitCaskHandle, Key) → ok| {error,any() } | 从 Bitcask 数据存储中删除一个键。 |
| bitcask:list_keys(BitCaskHandle) → [Key]| {error, any() } | 列出 Bitcask 数据存储中的所有键。 |
| bitcask:fold(BitCaskHandle, Fun, Acc0) → Acc | 遍历 Bitcask 数据存储中的所有 K/V 对。Fun 的期望形式为:F(K,V,Acc0) → Acc。 |
| bitcask:merge(DirectoryName) → ok| {error,any() } | 将 Bitcask 数据存储内的多个数据文件合并为更紧凑的形式。同时生成提示文件以加速启动。 |
| bitcask:sync(BitCaskHandle) → ok | 强制将所有挂起的写入同步到磁盘。 |
| bitcask:close(BitCaskHandle) → ok | 关闭 Bitcask 数据存储并将所有挂起的写入(如果有)刷新到磁盘。 |
如您所见,Bitcask 非常易于使用。享受吧!
原文链接: Bitcask A Log-Structured Hash Table for Fast Key/Value Data