Appearance
缓存
一、定义 --ces
存储器的基本性质
- 存取时间越快,每“位”的价格越高
- 容量越大,价格越低
- 容量越大,存取速度越慢
由于存储介质的特性,存储介质的读写速度有很大的差异,为了提高数据的读取速度,将数据存储在读取速度较快的存储介质中,这种存储介质就是缓存。
二、缓存系统效率
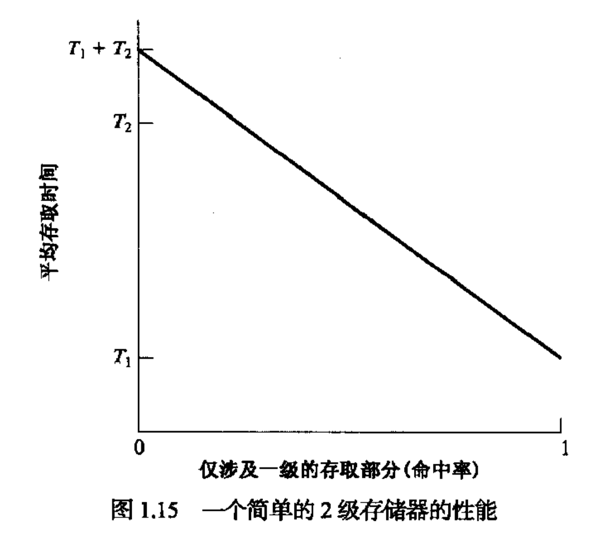
缓存系统的速度和命中率成正比。具体的关系为:
其中:
- t: 缓存系统的整体存取时间
- T1: 一级存储器的存取时间
- T2: 二级存储器的存取时间
- H: 缓存命中率
三、缓存分类
本地缓存
本地缓存是指缓存和应用在同一个进程内,缓存的数据是应用进程的私有数据。
- 优点是: 距离应用实例近,访问速度更快。
- 缺点是: 缓存数据是应用实例私有的,不同应用实例之间不能共享。不同应用实例之间的缓存数据很可能不一致,就需要更频繁地淘汰缓存数据。
本地缓存实现
- Ehcache
- guava cache
服务端缓存(分布式缓存)
缓存数据和应用在不同的进程内,缓存的数据是多应用实例共享的。
- 优点是: 缓存数据可以共享,不同应用实例之间的缓存数据一致。
- 缺点是: 距离应用实例远,访问速度慢。
分布式缓存实现
- memcached
- redis
四、缓存的问题和解决方案
1. 缓存过期策略
缓存系统一般会实现一个过期策略,当数据长时间未被访问时,缓存系统会淘汰该数据。常用的过期策略有:
- 定时过期
为每个设置过期时间的 key 都需要创建一个定时器,到过期时间就会立即清除
- 惰性过期
只有当访问一个 key 时,才会判断该 key 是否已过期,并且进行删除操作
- 定期过期
添加一个即将过期的缓存字典,每隔一定的时间,会扫描一定数量的 key,并清除其中已过期的 key
2. 缓存淘汰策略
相对于数据库,缓存系统一般空间有限,当缓存数据量超过一定阈值时,需要淘汰部分数据。 常用淘汰策有:
- 先进先出(FIFO)
- 最近最少使用(LRU)
- 最近最不使用(LFU)
- 随机淘汰
淘汰策略需要灵活配置,根据应用场景选择合适的淘汰策略。如果数据获取成本比较高,可以考虑让数据保留在缓存中
3. 缓存穿透
缓存和主存中都没有的数据,而用户不断发起请求,导致请求直接穿透到主存中。 解决:
- 缓存空对象
- 布隆过滤器
4. 缓存击穿
缓存击穿,是指一个key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个屏障上凿开了一个洞。
解决:
- 使用互斥锁(mutex key)
这种思路比较简单,就是让一个线程回写缓存,其他线程等待回写缓存线程执行完,重新读缓存即可。
- 热点数据永不过期
- 物理不过期,针对热点key不设置过期时间
- 逻辑过期,把过期时间存在key对应的value里,如果发现要过期了,通过一个后台的异步线程进行缓存的构建
5. 缓存雪崩
缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,请求直接落到数据库上,引起数据库压力过大甚至宕机。和缓存击穿不同的是,缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
解决方案
- 均匀过期
设置不同的过期时间,让缓存失效的时间点尽量均匀。通常可以为有效期增加随机值或者统一规划有效期。
- 加互斥锁
跟缓存击穿解决思路一致,同一时间只让一个线程构建缓存,其他线程阻塞排队。
- 缓存永不过期
跟缓存击穿解决思路一致,缓存在物理上永远不过期,用一个异步的线程更新缓存。
- 双层缓存策略
使用主备两层缓存:
- 主缓存:有效期按照经验值设置,设置为主读取的缓存,主缓存失效后从数据库加载最新值。
- 备份缓存:有效期长,获取锁失败时读取的缓存,主缓存更新时需要同步更新备份缓存。
五、缓存和DB的同步
如何在缓存和主存储系统之间同步数据,主要有三种策略:
Read-Through (Cache-Aside)
基本流程
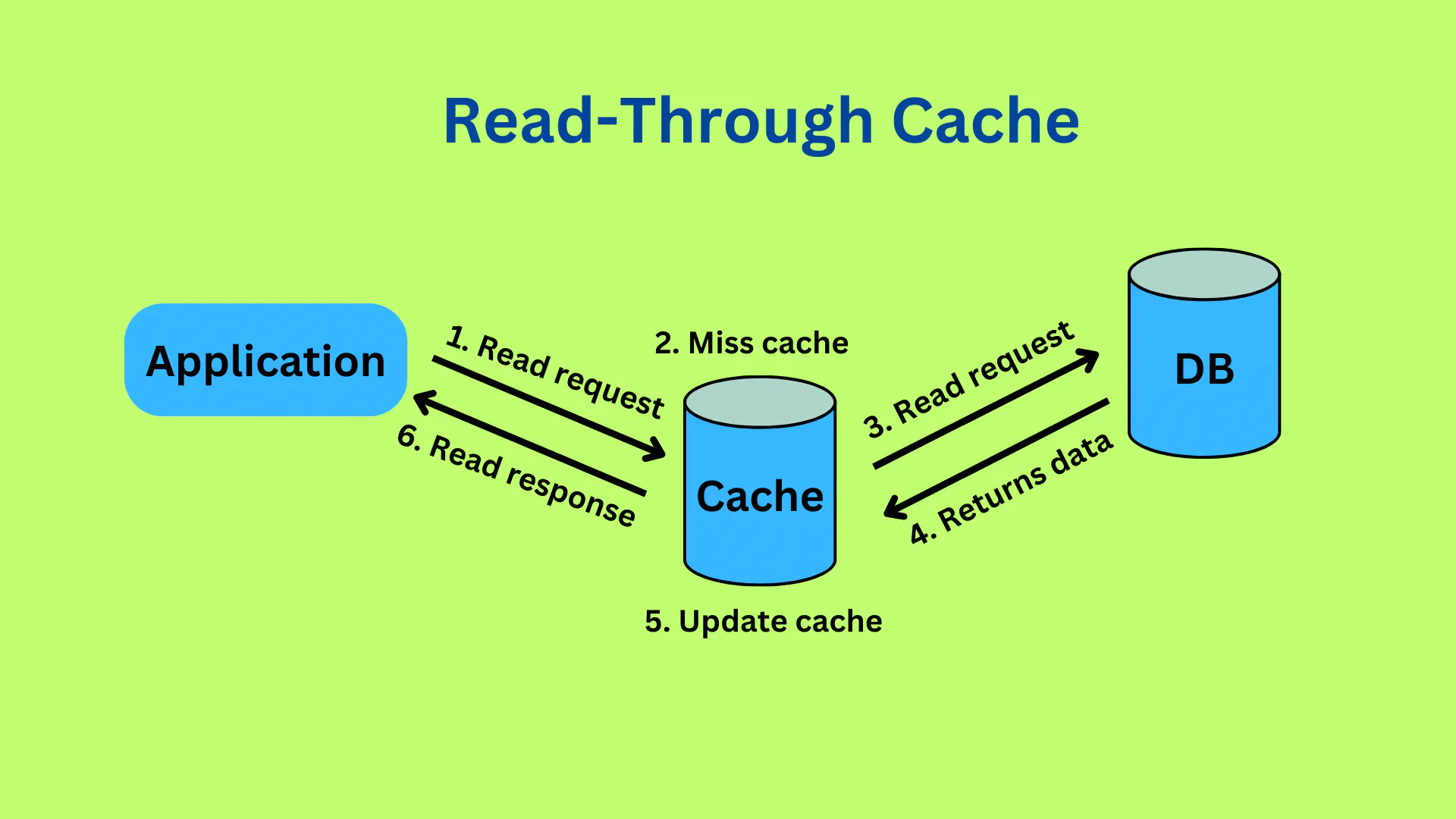
优点
- 频繁读取时,减少了数据库的压力(其实就是懒加载的优点)
缺点
- 首次读取的时候延迟高
Write-Through
基本流程
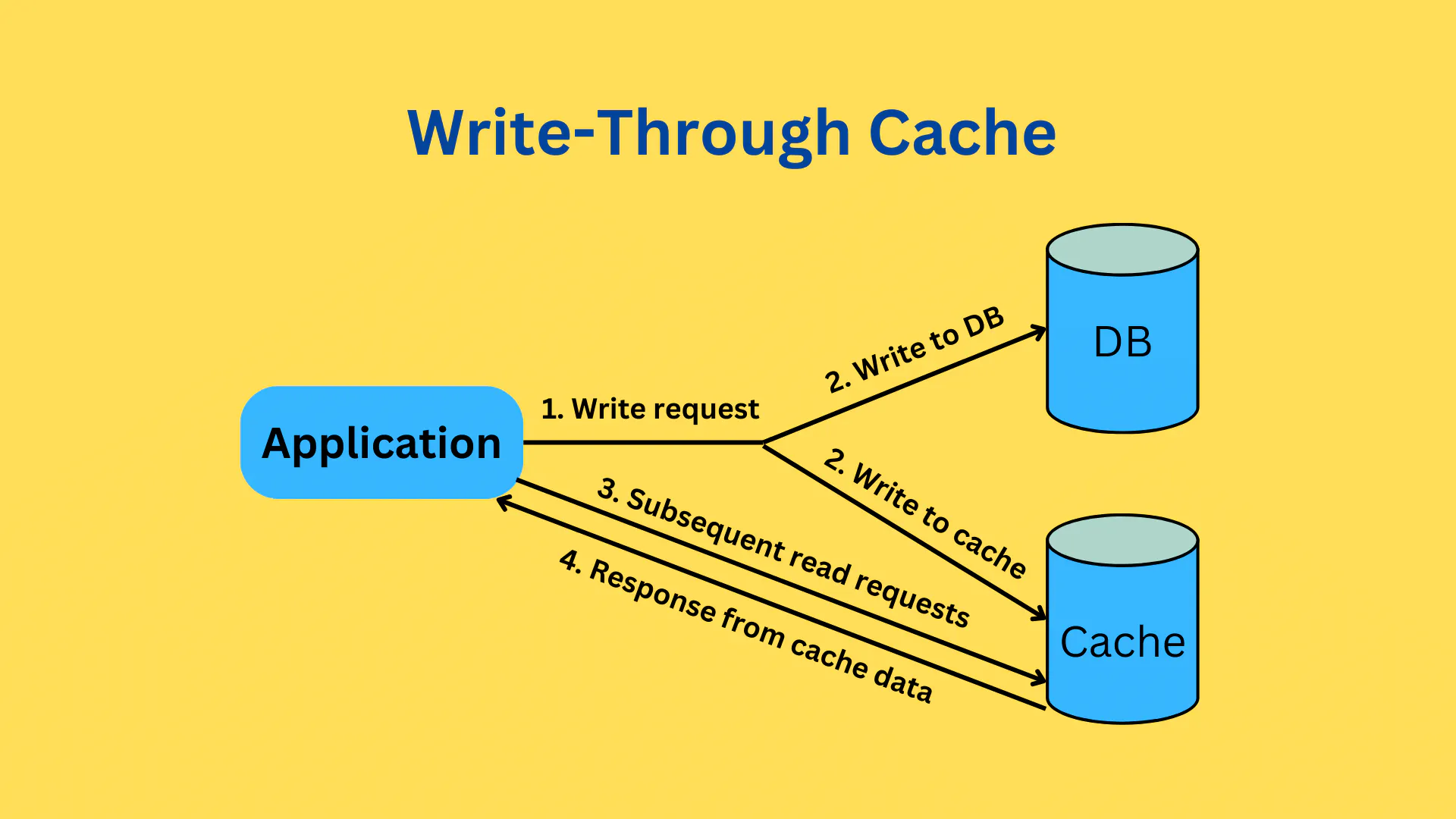
优点
- 保证了缓存和主存数据一致性
缺点
- 写延时,因为数据需要同时写入缓存和主存
- 访问频率低的数据,也被写入缓存,缓存利用率低
Write-Behind
基本流程
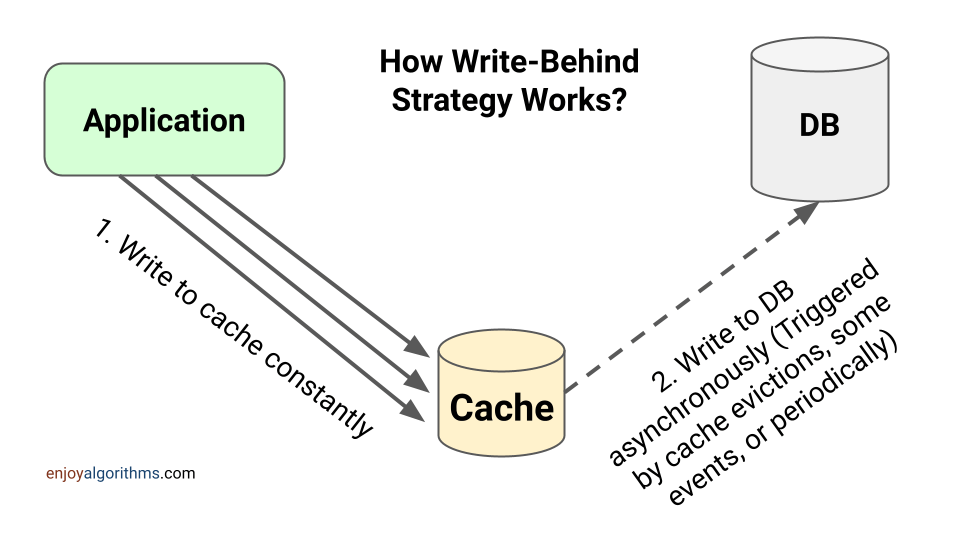
优点
- 写数据时,只写入缓存,不写入主存,减少主存压力
- 写入速度快
缺点
- 有丢数据的风险